一、搭建eBPF开发环境并开发第一个eBPF程序
开发环境简介
笔者使用阿里云服务器 规格:2vCPU/2GiB ,云盘类型大小:ESSD Entry云盘 40GiB (2120 IOPS)
使用以下命令查看:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# 查看内核版本号 以及其他系统信息
uname -a
# 查看发行版本
lsb_release -a
# 或者使用
cat /etc/os-release
# 查看CPU信息
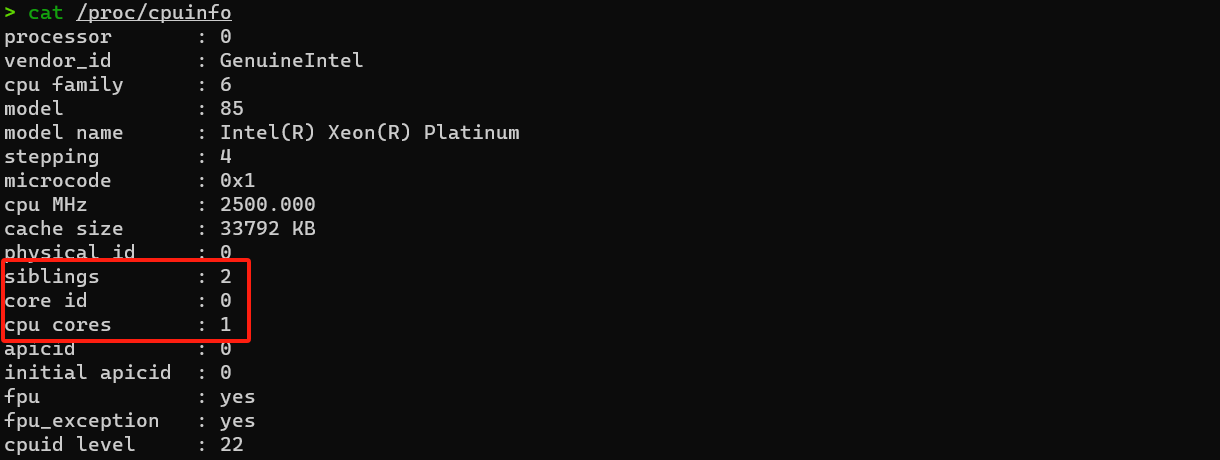
cat /proc/cpuinfo
# 查看内存使用信息
free -h
# 查看磁盘空间使用情况
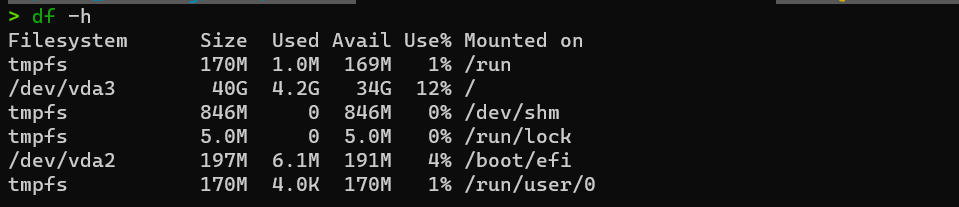
df -h
|
- 内核版本号

- 发行版本

- CPU信息
- 内存使用情况(free 内存使用情况)

- 磁盘空间使用情况(disk free)
环境搭建
安装 eBPF 开发和运行所需要的开发工具,这包括:
- 将 eBPF 程序编译成字节码的 LLVM;
- C 语言程序编译工具 make;
- 最流行的 eBPF 工具集 BCC 和它依赖的内核头文件;
- 与内核代码仓库实时同步的 libbpf;
- 同样是内核代码提供的 eBPF 程序管理工具 bpftool。
使用以下命令安装必要的开发工具:
1
2
3
4
5
|
# For Ubuntu20.10+
sudo apt-get install -y make clang llvm libelf-dev libbpf-dev bpfcc-tools libbpfcc-dev linux-tools-$(uname -r) linux-headers-$(uname -r)
# For RHEL8.2+
sudo yum install libbpf-devel make clang llvm elfutils-libelf-devel bpftool bcc-tools bcc-devel
|
检查linux下是否有python3,如下:
1
2
3
4
|
python3 --version
# 检查pip包是否安装
# pip是Python的软件包管理器,用于安装第三方库和模块
pip3 --version
|
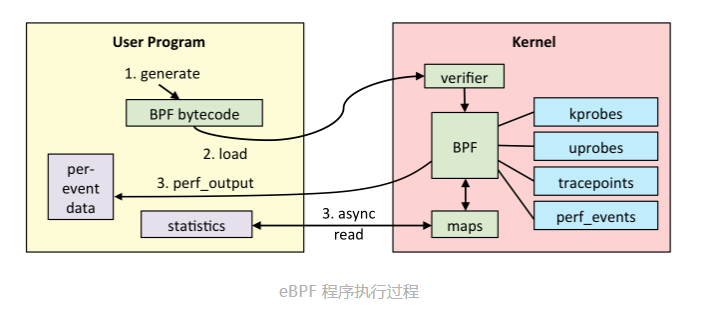
eBPF执行过程
-
第一步,使用 C 语言开发一个 eBPF 程序;
-
第二步,借助 LLVM 把 eBPF 程序编译成 BPF 字节码;
-
第三步,通过 bpf 系统调用,把 BPF 字节码提交给内核;
-
第四步,内核验证并运行 BPF 字节码,并把相应的状态保存到 BPF 映射中;
-
第五步,用户程序通过 BPF 映射查询 BPF 字节码的运行状态。
开发第一个eBPF程序
- 第一个
.c文件的eBPF程序
1
2
3
4
5
6
|
// The first program of eBPF
//
int hello_world(void *ctx) {
bpf_trace_printk("Hello, World!");
return 0;
}
|
其中, bpf_trace_printk() 是一个最常用的 BPF 辅助函数,它的作用是输出一段字符串。不过,由于 eBPF 运行在内核中,它的输出并不是通常的标准输出(stdout),而是内核调试文件 /sys/kernel/debug/tracing/trace_pipe ,你可以直接使用 cat 命令来查看这个文件的内容
- 使用python和BCC库开发一个用户程序
1
2
3
4
5
6
7
8
9
10
11
12
13
|
#!/usr/bin/env python3
# 1. import bcc library
from bcc import BPF
# 2. load BPF program
b = BPF(src_file="hello.c")
# 3. attach kprobe
b.attach_kprobe(event="do_sys_openat2", fn_name="hello_world")
# 4. read and print /sys/kernel/debug/tracing/trace_pipe
b.trace_print()
|
- 执行eBPF程序
需要注意的是, eBPF 程序需要以 root 用户来运行,非 root 用户需要加上 sudo 来执行
输出如下:
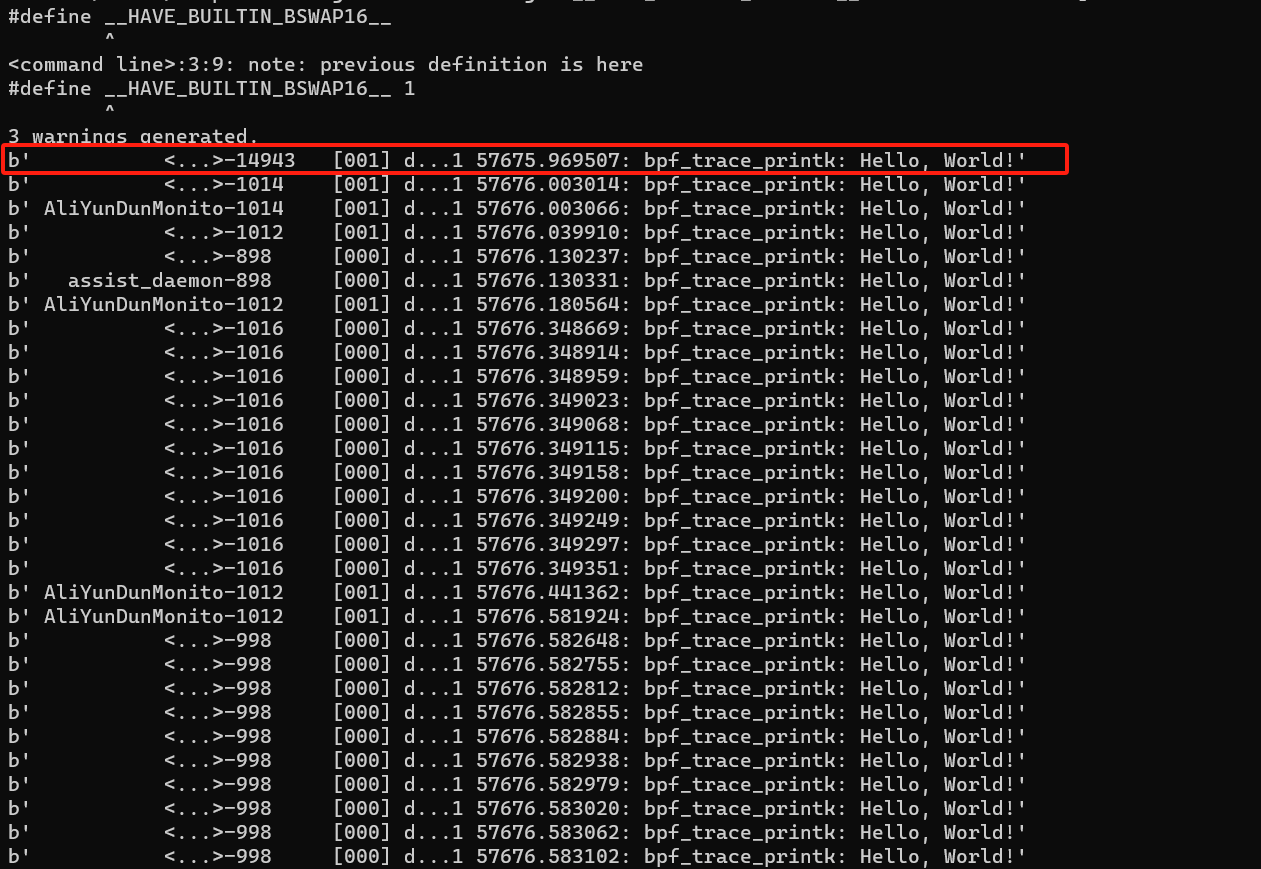
输出的格式可由 /sys/kernel/debug/tracing/trace_options 来修改。前面这个默认的输出中,每个字段的含义如下所示:
- assist_daemon-898:表示进程名字和ID
- $[000]$:表示CPU编号
- d…1 :表示一系列选项
- 57675.969507:表示时间戳
- bpf_trace_printk:表示函数名
- “Hello, World!":调用
bpf_trace_printk()传入的字符串
上述的程序有比较多的缺点:
- 跟踪的是打开文件的系统调用,除了调用这个接口进程的名字之外,被打开的文件名也应该在输出中;
- bpf_trace_printk() 的输出格式不够灵活,像是 CPU 编号、bpf_trace_printk 函数名等内容没必要输出;
- ……
实际上,并不推荐通过内核调试文件系统输出日志的方式。一方面,它会带来很大的性能问题;另一方面,所有的 eBPF 程序都会把内容输出到同一个位置,很难根据 eBPF 程序去区分日志的来源。
改进第一个eBPF程序
BPF 程序可以利用 BPF 映射(map)进行数据存储,而用户程序也需要通过 BPF 映射,同运行在内核中的 BPF 程序进行交互。
为了解决上面提到的第一个问题:即获取被打开文件名的问题,我们就要引入 BPF 映射
BCC 定义了一系列的库函数和辅助宏定义。比如,你可以使用 BPF_PERF_OUTPUT 来定义一个 Perf 事件类型的 BPF 映射,代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
|
#include <uapi/linux/openat2.h>
#include <linux/sched.h>
// 定义数据结构
struct data_t {
u32 pid;
u64 ts;
char comm[TASK_COMM_LEN];
char fname[NAME_MAX];
};
// 定义性能事件映射
BPF_PERF_OUTPUT(events);
|
在 eBPF 程序中,填充这个数据结构,并调用 perf_submit() 把data数据提交到刚才定义的 BPF 映射中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
// 定义kprobe处理函数
int hello_world(struct pt_regs *ctx, int dfd, const char __user *filename, struct open_how *how)
{
struct data_t data = {};
// 获取PID 和 时间
data.pid = bpf_get_current_pid_tgid();
data.ts = bpf_ktime_get_ns();
// 获取进程名
if (bpf_get_current_comm(&data.comm, sizeof(data.comm) ) == 0)
{ // 读取进程打开的文件名
bpf_probe_read(&data.fname, sizeof(data.fname), (void*)filename);
}
// 提交性能事件
events.perf_submit(ctx, &data, sizeof(data));
return 0;
}
|
以 bpf 开头的函数都是 eBPF 提供的辅助函数,解释一下上述用到的几个函数作用:
bpf_get_current_pid_tgid 用于获取进程的 TGID 和 PID。因为这儿定义的 data.pid 数据类型为 u32,所以高 32 位舍弃掉后就是进程的 PID;bpf_ktime_get_ns 用于获取系统自启动以来的时间,单位是纳秒;bpf_get_current_comm 用于获取进程名,并把进程名复制到预定义的缓冲区中;bpf_probe_read 用于从指定指针处读取固定大小的数据,这里则用于读取进程打开的文件名。
有了BPF映射,用户态进程可以直接从BPF映射中读取内核eBPF程序的运行状态。
问题:如何从用户态读取 BPF 映射内容并输出到标准输出(stdout)呢?
在BCC中,与eBPF程序中的BPF_PERF_OUTPUT相对应的用户态辅助函数是 open_perf_buffer() 。它需要传入一个回调函数,用于处理从 Perf 事件类型的 BPF 映射中读取到的数据。具体的使用方法如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
from bcc import BPF
# 1. load BPF program
b = BPF(src_file="trace-open.c")
b.attach_kprobe(event="do_sys_openat2", fn_name="hello_world")
# 2. print header
print("%-18s %-20s %-6s %-16s" % ("TIME(S)", "COMM", "PID", "FILE") )
# 3. define the callback for perf event
start = 0
def print_event(cpu, data, size):
global start
# BPF程序对象b中获取定义的事件属性,之后调用event方法解析缓冲区中data数据(也就是前边定义的数据结构 实例对象)
event = b["events"].event(data)
if start == 0:
start = event.ts
time_s = (float(event.ts - start)) / 1000000000
print("%-18.9f %-20s %-6d %-16s" % (time_s, event.comm, event.pid, event.fname))
# 4. loop with callback to print_event
# `b["events"]`是一个字典形式的属性访问,它获取了`BPF`对象`b`的`events`属性。
# 在`bcc`库中,`events`是一个特殊的属性,用于访问BPF程序中定义的事件
# open_perf_buffer 是打开一个性能事件 events 的缓冲区
# 将 回调函数 print_event 绑定到 性能缓冲区中
b["events"].open_perf_buffer(print_event)
while True:
try:
# 调用 perf_buffer_poll 轮询性能事件的 缓冲区
b.perf_buffer_poll()
except KeyboardInterrupt:
exit()
|
解释一下上面每一行代码的含义:
BPF和attach_kprobe:加载 eBPF 程序并挂载到内核探针上- 第二处:输出一行Header字符串,表示数据格式头
print_event:定义一个数据处理的回调函数,打印进程的名字、PID 以及它调用 openat 时打开的文件;open_perf_buffer:定义了名为"events"的Perf事件映射perf_buffer_poll:在一个循环中读取映射内容,并执行回调函数输出进程信息
保存文件trace-open.c以及trace-open.py,然后运行程序如下:
1
|
sudo python3 trace-open.py
|
输出如下:
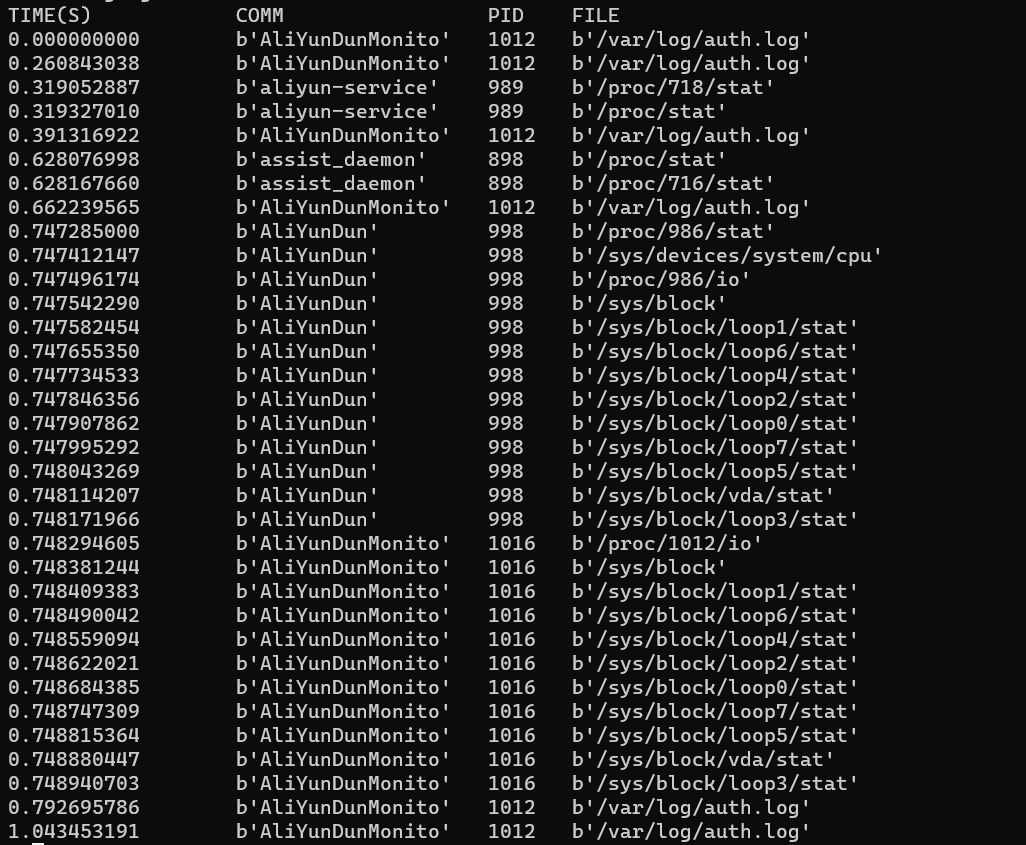
相对于前面的 Hello World,它的输出不仅格式更为清晰,还把进程打开的文件名输出出来了,这在排查频繁打开文件相关的性能问题时尤其有用。
小结
上面学习流程包括:搭建eBPF开发环境,安装eBPF开发时常用的工具和依赖库,使用BCC从零开发一个跟踪openat()系统调用的eBPF程序。
通常,开发一个eBPF程序需要经过以下步骤:
- 开发C语言eBPF程序
- 借助LLVM 把 eBPF程序 编译 成BPF字节码(BCC框架中借助
BPF(src_file="xxx")实现了编译程序 并且加载字节码到内核 )
- 加载BPF字节码到内核(通过 bpf系统调用,上边BCC框架中借助
attach_kprobe接口来实现跟踪对应的事件event 触发对应的回调函数 fn_name )
- 内核验证并运行BPF字节码(将 相应的状态保存到BPF映射中)
- 用户程序读取BPF映射
使用BCC好处:把上面几个步骤通过内置的框架抽象起来,并提供简单易用的Python接口,可以帮助简化eBPF程序的开发。
BCC 提供的一系列工具不仅可以直接用在生产环境中,还是学习和开发新的 eBPF 程序的最佳参考示例。
通常来说,eBPF程序包括 用户态程序 和 内核态程序。BCC封装了很多库,可以简化用户态程序开发过程,不用BCC用户态程序一般会比较长。
二、eBPF虚拟机内核运行过程
eBPF内核运行时模块
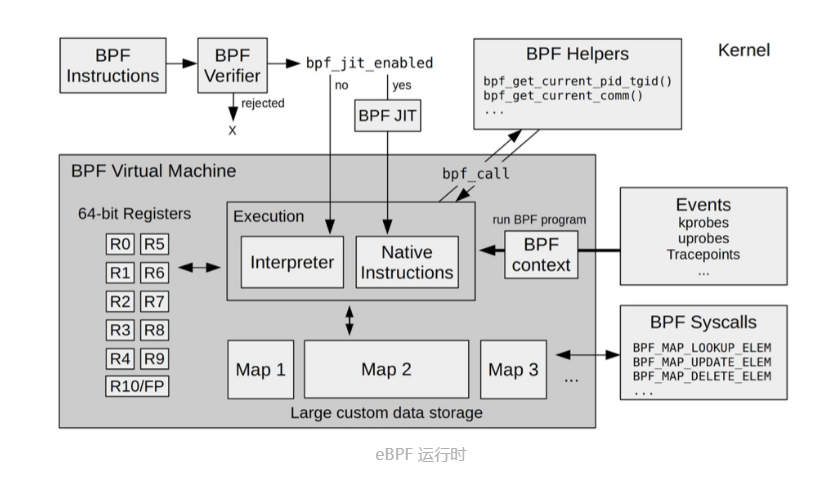
-
11个64位寄存器,一个程序计数器 和 一个512字节的栈组成的存储模块。 该模块用于控制eBPF程序执行。
- R0寄存器:存储函数调用 和 eBPF程序 返回值,函数调用最多只有一个返回值
- R1~R5寄存器:函数调用的参数,函数调用参数不超过5个
- R10寄存器:只读寄存器,用于从栈中读取数据
-
即时编译器(JIT):将eBPF 字节码 编译成 本地机器指令
-
BPF映射(map):用于提供大块的存储。存储可被用户空间程序 用来进行访问,进而控制 eBPF 程序的运行状态。
功能简介:可以查看 eBPF程序运行状态,并且可以导出 eBPF程序指令。相当于 objdump查看 可执行程序的指令。(反汇编)
查看运行状态命令:
1
2
3
4
5
6
7
|
sudo bpftool prog list
89: kprobe name hello_world tag 38dd440716c4900f gpl
loaded_at 2021-11-27T13:20:45+0000 uid 0
xlated 104B jited 70B memlock 4096B
btf_id 131
pids python3(152027)
|
89 是这个 eBPF 程序的编号,kprobe 是程序的类型,而 hello_world 是程序的名字。
导出指定编号的 eBPF程序指令:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
sudo bpftool prog dump xlated id 89
int hello_world(void * ctx):
; int hello_world(void *ctx)
0: (b7) r1 = 33 /* ! */
; ({ char _fmt[] = "Hello, World!"; bpf_trace_printk_(_fmt, sizeof(_fmt)); });
1: (6b) *(u16 *)(r10 -4) = r1
2: (b7) r1 = 1684828783 /* dlro */
3: (63) *(u32 *)(r10 -8) = r1
4: (18) r1 = 0x57202c6f6c6c6548 /* W ,olleH */
6: (7b) *(u64 *)(r10 -16) = r1
7: (bf) r1 = r10
;
8: (07) r1 += -16
; ({ char _fmt[] = "Hello, World!"; bpf_trace_printk_(_fmt, sizeof(_fmt)); });
9: (b7) r2 = 14
10: (85) call bpf_trace_printk#-61616
; return 0;
11: (b7) r0 = 0
12: (95) exit
|
分号开头的部分,正是 C 代码,而其他行则是具体的 BPF 指令。具体每一行的 BPF 指令又分为三部分:
- 第一部分,冒号前面的数字 0-12 ,代表 BPF 指令行数;
- 第二部分,括号中的 16 进制数值,表示 BPF 指令码。 它的具体含义你可以参考 IOVisor BPF 文档,比如第 0 行的 0xb7 表示为 64 位寄存器赋值。
- 第三部分,括号后面的部分,就是 BPF 指令的伪代码。
一般来说,只把BPF指令作为 排查eBPF程序疑难杂症时才考虑。
BPF指令加载后如何运行的:BPF 指令加载到内核后, BPF 即时编译器会将其编译成本地机器指令,最后才会执行编译后的机器指令。
了解eBPF程序 执行过程
了解 BPF 指令的加载过程,就可以从 BCC 执行 eBPF 程序的过程入手。
怎么才能查看到 BCC 的执行过程呢?跟踪它的系统调用过程。
1
2
|
# -ebpf表示只跟踪bpf系统调用
sudo strace -v -f -ebpf ./hello.py
|
命令功能:使用strace命令来跟踪BPF系统调用,通过参数"-ebpf"指定只跟踪BPF系统调用,然后执行"./hello.py"程序。strace命令将会输出相关的系统调用信息,包括BPF系统调用的细节

无法直接 ./trace-open.py 或者 ./hello.py 方式运行程序,原因:没有在脚本程序上边添加 解释器路径。。。。

解决方案:
脚本上边添加解释器路径:
接着,给hello.py脚本添加可执行权限,如下:
可以看到如下:
上边 ./hello.py执行不对,还是由于第一行脚本注释没有写好。接着执行:
1
|
strace -v -f -ebpf ./hello.py
|
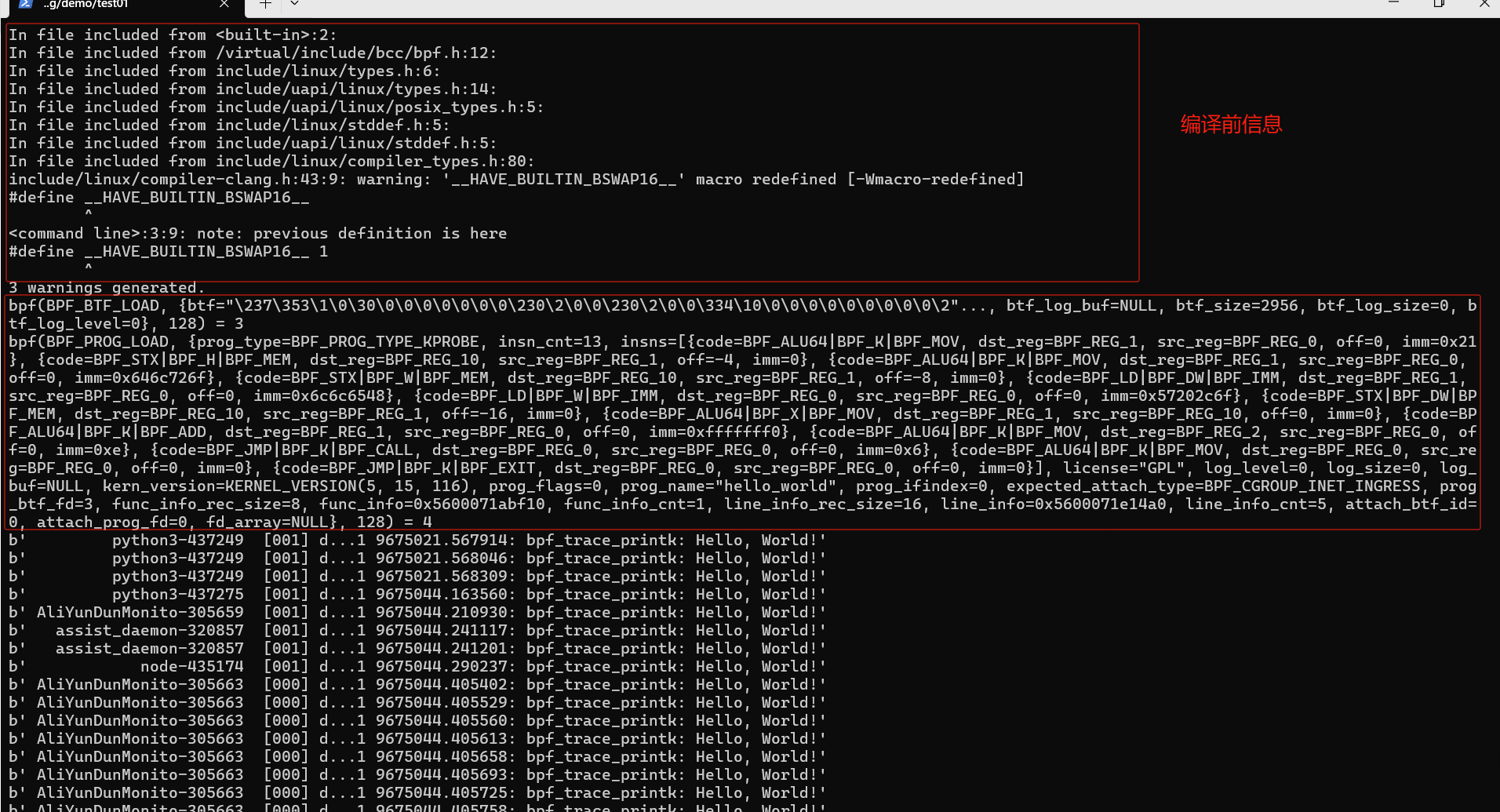
bpf系统调用格式,只需要三个参数:
1
|
int bpf(int cmd, union bpf_attr *attr, unsigned int size);
|
使用上述的strace命令来追踪 一个eBPF程序系统调用过程,可以看到上边输出内容如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
bpf(BPF_BTF_LOAD,
{
btf="\237\353\1\0\30\0\0\0\0\0\0\0\230\2\0\0\230\2\0\0\334\10\0\0\0\0\0\0\0\0\0\2"...,
btf_log_buf=NULL,
btf_size=2956,
btf_log_size=0,
btf_log_level=0
},
128) = 3
bpf(BPF_PROG_LOAD,
{
prog_type=BPF_PROG_TYPE_KPROBE,
insn_cnt=13,
insns=[
{code=BPF_ALU64|BPF_K|BPF_MOV, dst_reg=BPF_REG_1, src_reg=BPF_REG_0, off=0, imm=0x21},
{code=BPF_STX|BPF_H|BPF_MEM, dst_reg=BPF_REG_10, src_reg=BPF_REG_1, off=-4, imm=0},
{code=BPF_ALU64|BPF_K|BPF_MOV, dst_reg=BPF_REG_1, src_reg=BPF_REG_0, off=0, imm=0x646c726f},
{code=BPF_STX|BPF_W|BPF_MEM, dst_reg=BPF_REG_10, src_reg=BPF_REG_1, off=-8, imm=0},
{code=BPF_LD|BPF_DW|BPF_IMM, dst_reg=BPF_REG_1, src_reg=BPF_REG_0, off=0, imm=0x6c6c6548},
{code=BPF_LD|BPF_W|BPF_IMM, dst_reg=BPF_REG_0, src_reg=BPF_REG_0, off=0, imm=0x57202c6f},
{code=BPF_STX|BPF_DW|BPF_MEM, dst_reg=BPF_REG_10, src_reg=BPF_REG_1, off=-16, imm=0},
{code=BPF_ALU64|BPF_X|BPF_MOV, dst_reg=BPF_REG_1, src_reg=BPF_REG_10, off=0, imm=0},
{code=BPF_ALU64|BPF_K|BPF_ADD, dst_reg=BPF_REG_1, src_reg=BPF_REG_0, off=0, imm=0xfffffff0},
{code=BPF_ALU64|BPF_K|BPF_MOV, dst_reg=BPF_REG_2, src_reg=BPF_REG_0, off=0, imm=0xe},
{code=BPF_JMP|BPF_K|BPF_CALL, dst_reg=BPF_REG_0, src_reg=BPF_REG_0, off=0, imm=0x6},
{code=BPF_ALU64|BPF_K|BPF_MOV, dst_reg=BPF_REG_0, src_reg=BPF_REG_0, off=0, imm=0},
{code=BPF_JMP|BPF_K|BPF_EXIT, dst_reg=BPF_REG_0, src_reg=BPF_REG_0, off=0, imm=0}
],
license="GPL", log_level=0, log_size=0, log_buf=NULL, kern_version=KERNEL_VERSION(5, 15, 116), prog_flags=0,
prog_name="hello_world", prog_ifindex=0, expected_attach_type=BPF_CGROUP_INET_INGRESS, prog_btf_fd=3, func_info_rec_size=8, func_info=0x5600071abf10, func_info_cnt=1, line_info_rec_size=16, line_info=0x5600071e14a0, line_info_cnt=5, attach_btf_id=0, attach_prog_fd=0, fd_array=NULL
},
128) = 4
|
- 第一个参数是
BPF_PROG_LOAD , 表示加载 BPF 程序。
- 第二个参数是
bpf_attr 类型的结构体(union),表示 BPF 程序的属性。其中,有几个需要你留意的参数,比如:
prog_type 表示 BPF 程序的类型,这儿是 BPF_PROG_TYPE_KPROBE ,跟我们 Python 代码中的 attach_kprobe 一致;insn_cnt (instructions count) 表示指令条数;insns (instructions) 包含了具体的每一条指令,这儿的 13 条指令跟我们前面 bpftool prog dump 的结果是一致的(具体的指令格式,你可以参考内核中 bpf_insn 的定义);prog_name 则表示 BPF 程序的名字,即 hello_world 。
- 第三个参数 128 表示属性的大小。
注意:了解了 bpf 系统调用的基本格式。对于 bpf 系统调用在内核中的实现原理,并不需要详细了解。只要知道它的具体功能,就可以掌握 eBPF 的核心原理了。
BPF 程序加载到内核后,并不会立刻执行,那么它什么时候才会执行呢?
eBPF 程序并不像常规的线程那样,启动后就一直运行在那里,它需要事件触发后才会执行。这些事件包括系统调用、内核跟踪点、内核函数和用户态函数的调用退出、网络事件,等等。
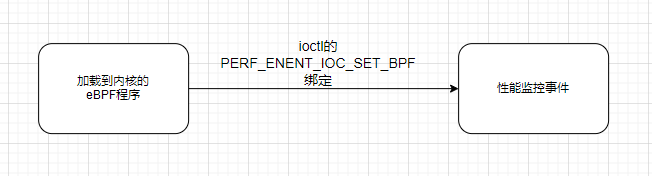
除了把 eBPF 程序加载到内核之外,还需要把加载后的程序跟具体的内核函数调用事件进行绑定。 在 eBPF 的实现中,诸如内核跟踪(kprobe)、用户跟踪(uprobe)等的事件绑定,都是通过 perf_event_open() 来完成的。
perf_event_open:用于创建 性能监控事件- 事件插桩:内核态跟踪事件 — kprobe插桩,用户态跟踪事件 — uprobe插桩
使用strace观测 BPF程序与 具体的内核函数调用事件进行绑定的过程:
1
|
strace -v -f ./hello.py
|
输出系统调用如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
...
/* 1) 加载BPF程序 */
bpf(BPF_PROG_LOAD,...) = 4
...
/* 2)查询事件类型 */
openat(AT_FDCWD, "/sys/bus/event_source/devices/kprobe/type", O_RDONLY) = 5
read(5, "6\n", 4096) = 2
close(5) = 0
...
/* 3)创建性能监控事件 */
perf_event_open(
{
type=0x6 /* PERF_TYPE_??? */,
size=PERF_ATTR_SIZE_VER7,
...
wakeup_events=1,
config1=0x7f275d195c50,
...
},
-1,
0,
-1,
PERF_FLAG_FD_CLOEXEC) = 5
/* 4)绑定BPF到kprobe事件 */
ioctl(5, PERF_EVENT_IOC_SET_BPF, 4) = 0
...
|
ps:由于真实输出的日志很混乱,上边的输出是来自极客时间。
看出 BPF 与性能事件的绑定过程分为以下几步:
- 借助 bpf 系统调用,加载 BPF 程序,并记住返回的文件描述符;
- 然后,查询 kprobe 类型的事件编号。BCC 实际上是通过
/sys/bus/event_source/devices/kprobe/type 来查询的;
- 接着,调用 perf_event_open 创建性能监控事件。比如,事件类型(type 是上一步查询到的 6)、事件的参数( config1 包含了内核函数 do_sys_openat2 )等;
- 最后,再通过 ioctl 的
PERF_EVENT_IOC_SET_BPF 命令,将 BPF 程序绑定到性能监控事件。
个人理解:eBPF程序 和 性能监控事件 是附属关系
小结
用高级语言开发的 eBPF 程序,需要首先编译为 BPF 字节码(即 BPF 指令),然后借助 bpf 系统调用加载到内核中,最后再通过性能监控等接口,与具体的内核事件进行绑定。这样,内核的性能监控模块才会在内核事件发生时,自动执行我们开发的 eBPF 程序。
了解eBPF在内核中实现原理,从BCC执行 eBPF程序过程入手,借助 bpftool、strace等工具,观测BPF指令的加载和执行过程。
高级语言开发一个eBPF程序,编译执行的过程:高级语言开发eBPF程序 —> BPF指令编译为BPF字节码 —> 借助 bpf系统调用加载到内核 —> 创建性能监控事件(使用接口 perf_event_open等) —> BPF程序绑定到性能监控事件。
三、eBPF编程接口介绍
eBPF程序怎么跟内核进行交互的?
eBPF程序如何跟内核事件进行绑定的?又该如何跟内核中的其他模块进行交互?
BPF系统调用 — 用户态程序编程接口
完整的eBPF程序通常包含两部分:用户态和内核态
- 用户态:负责eBPF程序的加载、事件绑定 以及 eBPF程序运行结果的定制化输出
- 内核态:运行在eBPF虚拟机中,负责 定制和控制系统的运行状态
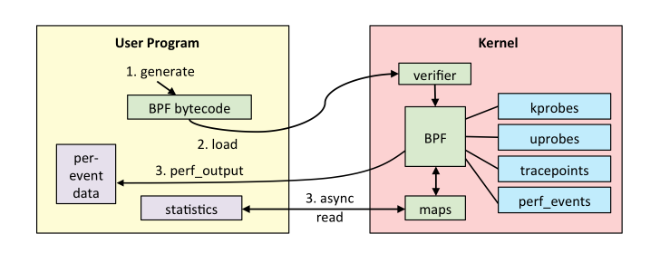
用户态程序与内核交互手段:通过系统调用来完成,常用的就是 bpf系统调用
查看bpf系统调用的man bpf,查询BPF系统调用函数接口如下:
1
2
3
|
#include <linux/bpf.h>
int bpf(int cmd, union bpf_attr *attr, unsigned int size);
|
- cmd :代表操作命令,比如:之前案例中的 BPF_PROG_LOAD 就是加载 eBPF 程序;
- attr:代表 bpf_attr 类型的 eBPF 属性指针,不同类型的操作命令需要传入不同的属性参数;
- size :代表属性的大小。
不同版本的内核所支持的 BPF 命令是不同的,具体支持的命令列表可以参考内核头文件 include/uapi/linux/bpf.h 中 bpf_cmd 的定义。笔者使用的服务器内核为 v5.15,支持BPF命令如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
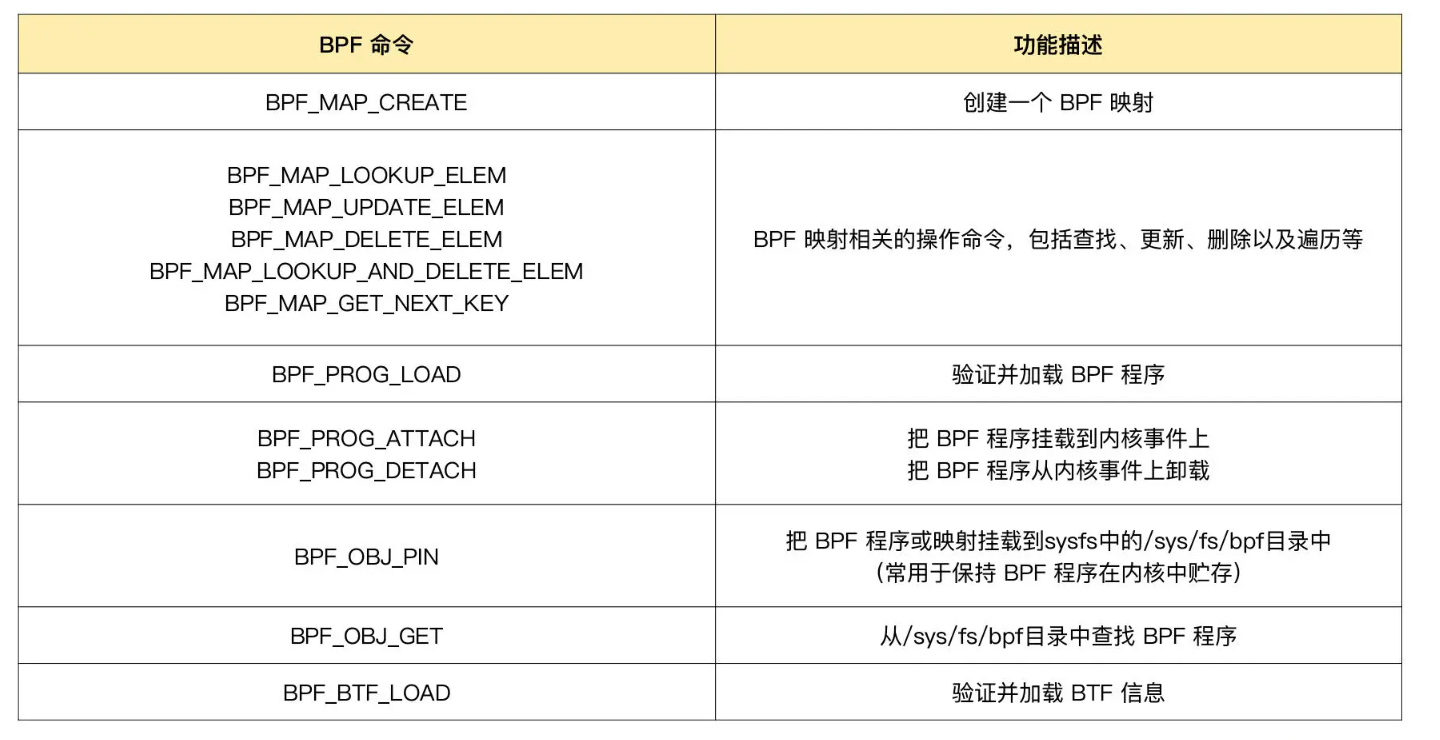
enum bpf_cmd {
BPF_MAP_CREATE,
BPF_MAP_LOOKUP_ELEM,
BPF_MAP_UPDATE_ELEM,
BPF_MAP_DELETE_ELEM,
BPF_MAP_GET_NEXT_KEY,
BPF_PROG_LOAD,
BPF_OBJ_PIN,
BPF_OBJ_GET,
BPF_PROG_ATTACH,
BPF_PROG_DETACH,
BPF_PROG_TEST_RUN,
BPF_PROG_RUN = BPF_PROG_TEST_RUN,
BPF_PROG_GET_NEXT_ID,
BPF_MAP_GET_NEXT_ID,
BPF_PROG_GET_FD_BY_ID,
BPF_MAP_GET_FD_BY_ID,
BPF_OBJ_GET_INFO_BY_FD,
BPF_PROG_QUERY,
BPF_RAW_TRACEPOINT_OPEN,
BPF_BTF_LOAD,
BPF_BTF_GET_FD_BY_ID,
BPF_TASK_FD_QUERY,
BPF_MAP_LOOKUP_AND_DELETE_ELEM,
BPF_MAP_FREEZE,
BPF_BTF_GET_NEXT_ID,
BPF_MAP_LOOKUP_BATCH,
BPF_MAP_LOOKUP_AND_DELETE_BATCH,
BPF_MAP_UPDATE_BATCH,
BPF_MAP_DELETE_BATCH,
BPF_LINK_CREATE,
BPF_LINK_UPDATE,
BPF_LINK_GET_FD_BY_ID,
BPF_LINK_GET_NEXT_ID,
BPF_ENABLE_STATS,
BPF_ITER_CREATE,
BPF_LINK_DETACH,
BPF_PROG_BIND_MAP,
};
|
ps:man文档中只包括 系统调用命令的使用,没有列出完整的bpf_cmd。
用户程序中常用的命令可以参考如下表格:
BPF 辅助函数 —— 内核态程序编程接口
eBPF程序并不能随意调用内核函数。内核定义了一系列的辅助函数,用于eBPF程序与内核其他模块进行交互。
前边样例中 ,.c文件中 Hello World示例就是内核态程序,bpf_trace_printk是最常用的辅助函数,用于向调试文件系统(/sys/kernel/debug/tracing/trace_pipe)写入调试信息
1
2
3
4
|
int hello_world(void *ctx) {
bpf_trace_printk("Hello, World!");
return 0;
}
|
补充:内核5.13版本开始,部分内核函数(如:tcp_slow_start()、tcp_reno_ssthresh() 等)也可以被 BPF 程序直接调用了,具体参考链接 Calling kernel functions from BPF。
需要注意的是,并不是所有的辅助函数都可以在 eBPF 程序中随意使用,不同类型的 eBPF 程序所支持的辅助函数是不同的。 对于,上边Hello World这类内核探针(kprobe)类型的内核态程序,可以使用 bpftool 查看当前系统支持的辅助函数列表:
1
2
3
|
bpftool feature probe
bpftool feature probe | grep bpf_ > bpf_function.txt
|
由于辅助函数列表太长,将其进行过滤之后并且重定向到 bpf_function.txt文本中,如下:
ps:vim中进入命令模式 :set number可以显示行数;正常模式,按下’G’可以将光标移动到最后一行。
这些辅助函数的详细定义,你可以在命令行中执行 man bpf-helpers ,或者参考内核头文件 include/uapi/linux/bpf.h ,来查看它们的详细定义和使用说明。将常用的辅助函数整理成如下表格:
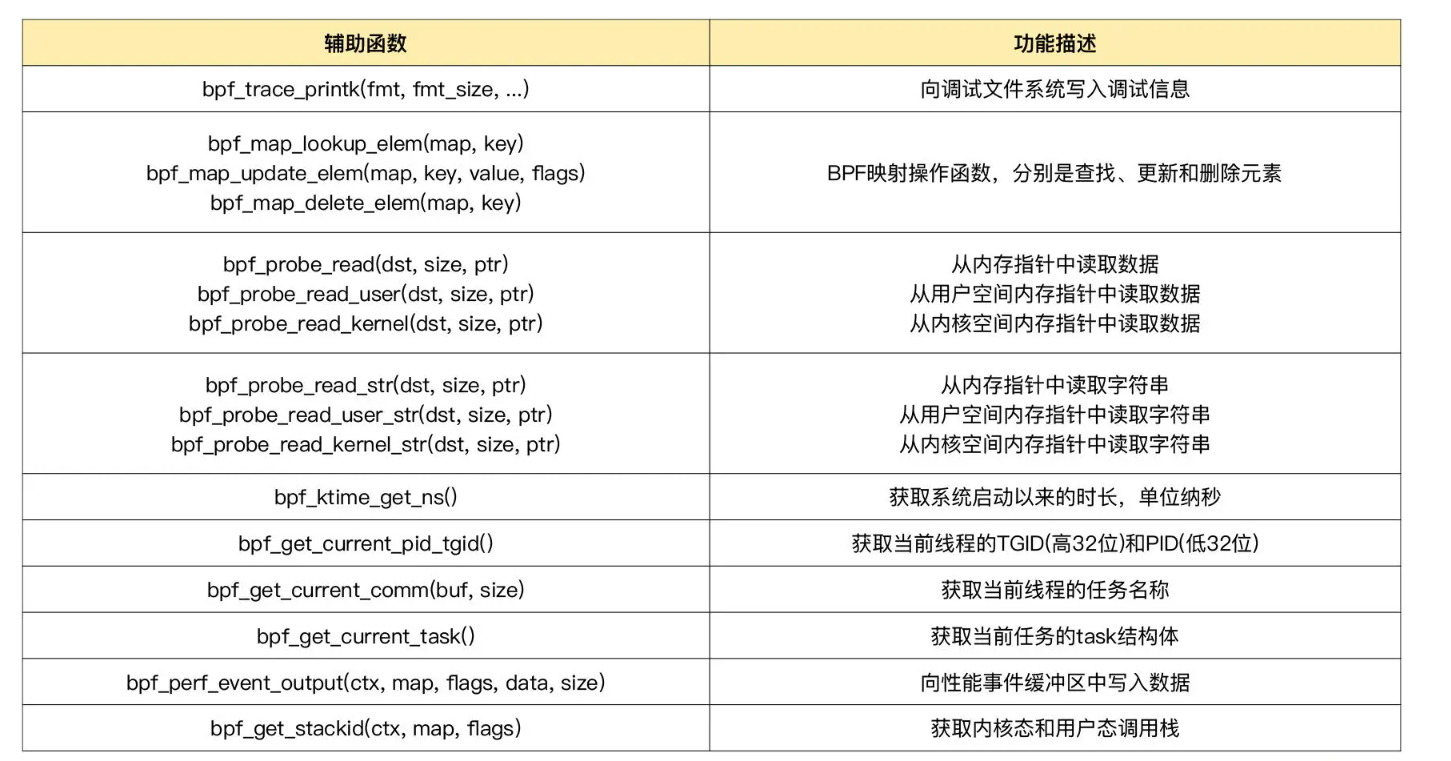
关注 以bpf_probe_read 开头的一系列函数。前边章节提到:eBPF 内部的内存空间只有寄存器和栈。 所以,要访问其他的内核空间或用户空间地址,就需要借助 bpf_probe_read 这一系列的辅助函数。 这些函数会进行安全性检查,并禁止缺页中断的发生。
eBPF 程序需要大块存储时,就不能像常规的内核代码那样去直接分配内存了,而是必须通过 BPF 映射(BPF Map)来完成。
可以简单理解为:BPF映射 就是 eBPF程序的虚拟内存空间。
BPF映射 —— “eBPF程序内存空间”
BPF 映射用于提供大块的键值存储,这些存储可被用户空间程序访问,进而获取 eBPF 程序的运行状态。 eBPF 程序最多可以访问 64 个不同的 BPF 映射,并且不同的 eBPF 程序也可以通过相同的 BPF 映射来共享它们的状态。
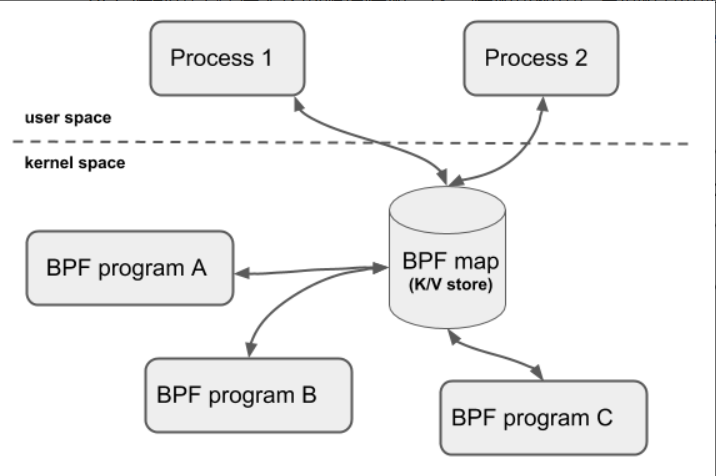
注意:BPF辅助函数 有很多系统调用命令 和 辅助函数都是用来访问BPF映射的。并没有 BPF映射的创建函数。 BPF映射只能通过用户态程序系统调用来创建。
使用下边这个示例代码来创建一个BPF映射,并返回映射的文件描述符,如下:
1
2
3
4
5
6
7
8
9
10
11
12
|
int bpf_create_map(enum bpf_map_type map_type,
unsigned int key_size,
unsigned int value_size, unsigned int max_entries)
{
union bpf_attr attr = {
.map_type = map_type,
.key_size = key_size,
.value_size = value_size,
.max_entries = max_entries
};
return bpf(BPF_MAP_CREATE, &attr, sizeof(attr));
}
|
上边设置创建映射最重要的是 设置映射类型。 通过 内核头文件include/uapi/linux/bpf.h 中的 bpf_map_type 定义了所有支持的映射类型,如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
enum bpf_map_type {
BPF_MAP_TYPE_UNSPEC,
BPF_MAP_TYPE_HASH,
BPF_MAP_TYPE_ARRAY,
BPF_MAP_TYPE_PROG_ARRAY,
BPF_MAP_TYPE_PERF_EVENT_ARRAY,
BPF_MAP_TYPE_PERCPU_HASH,
BPF_MAP_TYPE_PERCPU_ARRAY,
BPF_MAP_TYPE_STACK_TRACE,
BPF_MAP_TYPE_CGROUP_ARRAY,
BPF_MAP_TYPE_LRU_HASH,
BPF_MAP_TYPE_LRU_PERCPU_HASH,
BPF_MAP_TYPE_LPM_TRIE,
BPF_MAP_TYPE_ARRAY_OF_MAPS,
BPF_MAP_TYPE_HASH_OF_MAPS,
BPF_MAP_TYPE_DEVMAP,
BPF_MAP_TYPE_SOCKMAP,
BPF_MAP_TYPE_CPUMAP,
BPF_MAP_TYPE_XSKMAP,
BPF_MAP_TYPE_SOCKHASH,
BPF_MAP_TYPE_CGROUP_STORAGE,
BPF_MAP_TYPE_REUSEPORT_SOCKARRAY,
BPF_MAP_TYPE_PERCPU_CGROUP_STORAGE,
BPF_MAP_TYPE_QUEUE,
BPF_MAP_TYPE_STACK,
BPF_MAP_TYPE_SK_STORAGE,
BPF_MAP_TYPE_DEVMAP_HASH,
BPF_MAP_TYPE_STRUCT_OPS,
BPF_MAP_TYPE_RINGBUF,
BPF_MAP_TYPE_INODE_STORAGE,
BPF_MAP_TYPE_TASK_STORAGE,
};
|
也可以使用如下的 bpftool 命令,来查询当前系统支持哪些映射类型:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
> bpftool feature probe | grep map_type
eBPF map_type hash is available
eBPF map_type array is available
eBPF map_type prog_array is available
eBPF map_type perf_event_array is available
eBPF map_type percpu_hash is available
eBPF map_type percpu_array is available
eBPF map_type stack_trace is available
eBPF map_type cgroup_array is available
eBPF map_type lru_hash is available
eBPF map_type lru_percpu_hash is available
eBPF map_type lpm_trie is available
eBPF map_type array_of_maps is available
eBPF map_type hash_of_maps is available
eBPF map_type devmap is available
eBPF map_type sockmap is available
eBPF map_type cpumap is available
eBPF map_type xskmap is available
eBPF map_type sockhash is available
eBPF map_type cgroup_storage is available
eBPF map_type reuseport_sockarray is available
eBPF map_type percpu_cgroup_storage is available
eBPF map_type queue is available
eBPF map_type stack is available
eBPF map_type sk_storage is available
eBPF map_type devmap_hash is available
eBPF map_type struct_ops is NOT available
eBPF map_type ringbuf is available
eBPF map_type inode_storage is available
eBPF map_type task_storage is available
|
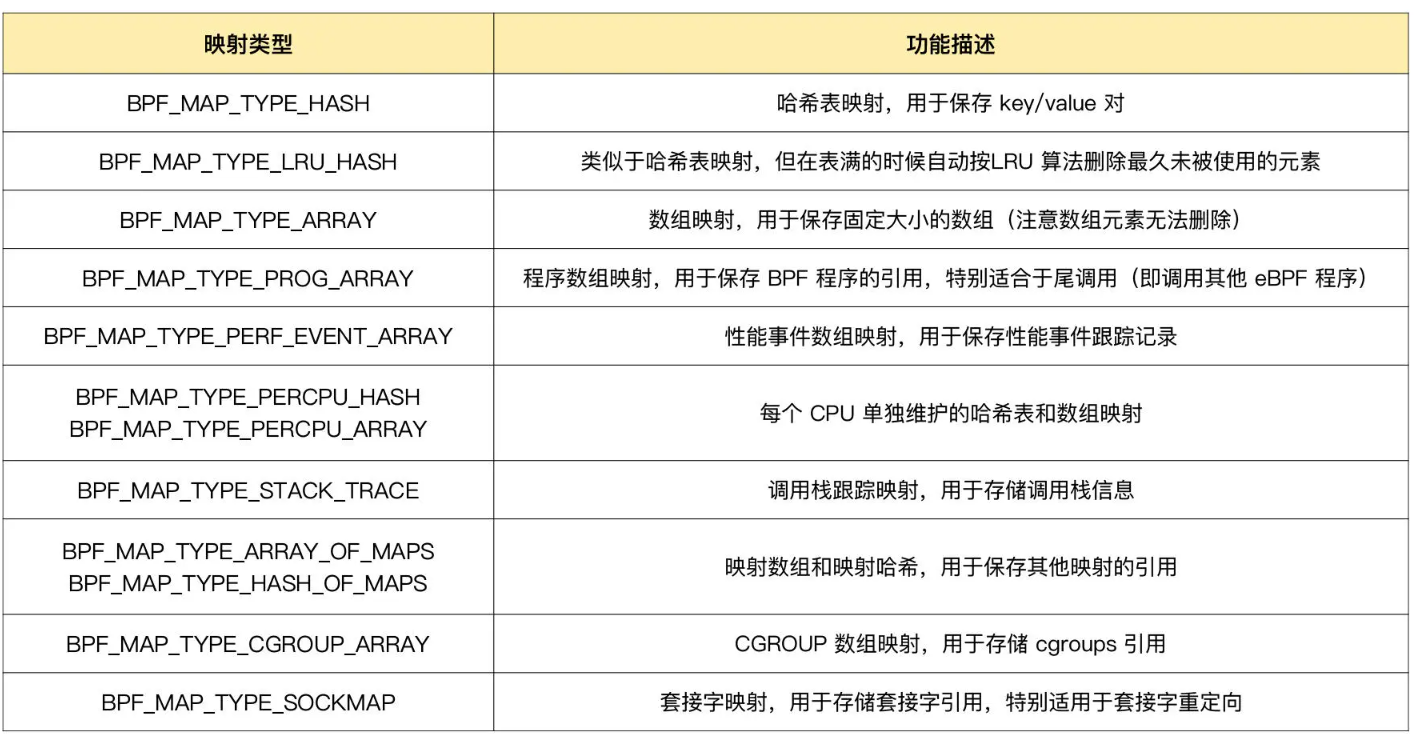
下边整理几种常用的映射类型 以及 功能和 使用场景:
使用BCC库创建BPF映射
使用预定义的宏来简化 BPF 映射的创建过程。 比如,对哈希表映射来说,BCC 定义了 BPF_HASH(name, key_type=u64, leaf_type=u64, size=10240),可以通过下面的几种方法来创建一个哈希表映射:
1
2
3
4
5
6
7
8
9
10
11
|
// 使用默认参数 key_type=u64, leaf_type=u64, size=10240
BPF_HASH(stats);
// 使用自定义key类型,保持默认 leaf_type=u64, size=10240
struct key_t {
char c[80];
};
BPF_HASH(counts, struct key_t);
// 自定义所有参数
BPF_HASH(cpu_time, uint64_t, uint64_t, 4096);
|
除了创建之外,映射的删除也需要特别注意。BPF 系统调用中并没有删除映射的命令,这是因为 BPF 映射会在用户态程序关闭文件描述符的时候自动删除(即close(fd) )。
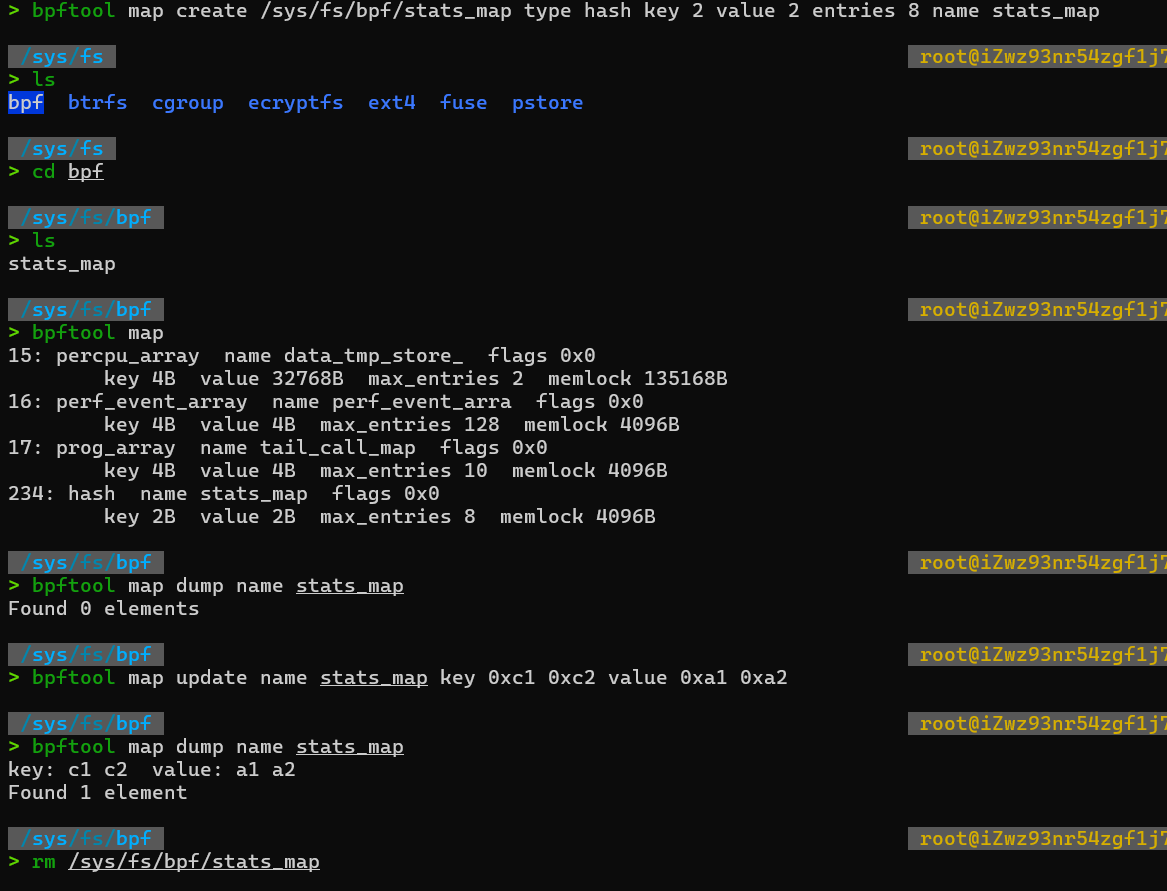
如果想在程序退出后还保留映射,就需要调用 BPF_OBJ_PIN 命令,将映射挂载到/sys/fs/bpf中,服务器上文件系统如下:

调试 BPF映射相关问题时,通过 bpftool来查看和操作映射的具体内容,如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
//创建一个哈希表映射,并挂载到/sys/fs/bpf/stats_map(Key和Value的大小都是2字节)
bpftool map create /sys/fs/bpf/stats_map type hash key 2 value 2 entries 8 name stats_map
//查询系统中的所有映射
bpftool map
//示例输出
//340: hash name stats_map flags 0x0
// key 2B value 2B max_entries 8 memlock 4096B
//向哈希表映射中插入数据
bpftool map update name stats_map key 0xc1 0xc2 value 0xa1 0xa2
//查询哈希表映射中的所有数据
bpftool map dump name stats_map
//示例输出
//key: c1 c2 value: a1 a2
//Found 1 element
//删除哈希表映射
rm /sys/fs/bpf/stats_map
|

小结
一个完整的 eBPF 程序,通常包含用户态和内核态两部分:
- 用户态程序需要通过 BPF 系统调用跟内核进行交互,进而完成 eBPF 程序加载、事件挂载以及映射创建和更新等任务;
- 内核态中,eBPF 程序也不能任意调用内核函数,而是需要通过 BPF 辅助函数完成所需的任务。尤其是在访问内存地址的时候,必须要借助
bpf_probe_read 系列函数读取内存数据,以确保内存的安全和高效访问。
在 eBPF 程序需要大块存储时,我们还需要根据应用场景,引入特定类型的 BPF 映射,并借助它向用户空间的程序提供运行状态的数据。
四、事件触发
本章介绍 各类eBPF程序的触发机制 以及 应用场景
经过前边的学习可以发现:并不是所有的辅助函数都可以在 eBPF 程序中随意使用,不同类型的 eBPF 程序所支持的辅助函数是不同的。
那么,eBPF 程序都有哪些类型,而不同类型的 eBPF 程序又有哪些独特的应用场景呢?
eBPF程序分类
eBPF 程序类型决定了一个 eBPF 程序可以挂载的事件类型和事件参数,内核中不同事件会触发不同类型的 eBPF 程序。
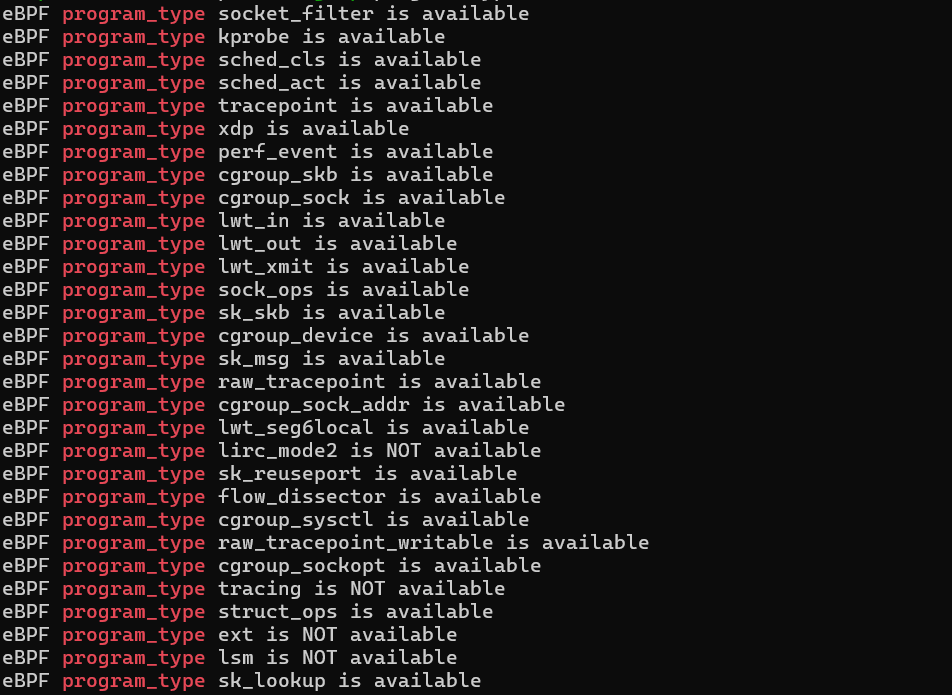
根据内核头文件include/uapi/linux/bpf.h 中 bpf_prog_type 的定义,Linux 内核 v5.15 已经支持 32种不同类型的 eBPF 程序(注意, BPF_PROG_TYPE_UNSPEC表示未定义):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
enum bpf_prog_type {
BPF_PROG_TYPE_UNSPEC,
BPF_PROG_TYPE_SOCKET_FILTER,
BPF_PROG_TYPE_KPROBE,
BPF_PROG_TYPE_SCHED_CLS,
BPF_PROG_TYPE_SCHED_ACT,
BPF_PROG_TYPE_TRACEPOINT,
BPF_PROG_TYPE_XDP,
BPF_PROG_TYPE_PERF_EVENT,
BPF_PROG_TYPE_CGROUP_SKB,
BPF_PROG_TYPE_CGROUP_SOCK,
BPF_PROG_TYPE_LWT_IN,
BPF_PROG_TYPE_LWT_OUT,
BPF_PROG_TYPE_LWT_XMIT,
BPF_PROG_TYPE_SOCK_OPS,
BPF_PROG_TYPE_SK_SKB,
BPF_PROG_TYPE_CGROUP_DEVICE,
BPF_PROG_TYPE_SK_MSG,
BPF_PROG_TYPE_RAW_TRACEPOINT,
BPF_PROG_TYPE_CGROUP_SOCK_ADDR,
BPF_PROG_TYPE_LWT_SEG6LOCAL,
BPF_PROG_TYPE_LIRC_MODE2,
BPF_PROG_TYPE_SK_REUSEPORT,
BPF_PROG_TYPE_FLOW_DISSECTOR,
BPF_PROG_TYPE_CGROUP_SYSCTL,
BPF_PROG_TYPE_RAW_TRACEPOINT_WRITABLE,
BPF_PROG_TYPE_CGROUP_SOCKOPT,
BPF_PROG_TYPE_TRACING,
BPF_PROG_TYPE_STRUCT_OPS,
BPF_PROG_TYPE_EXT,
BPF_PROG_TYPE_LSM,
BPF_PROG_TYPE_SK_LOOKUP,
BPF_PROG_TYPE_SYSCALL, /* a program that can execute syscalls */
};
|
对于具体内核,不同内核版本和编译配置选项不同,一个内核不会支持所有的程序类型,可以使用如下命令进行查询当前系统所支持的程序类型:
1
|
bpftool feature probe | grep program_type
|
根据具体功能和应用场景不同,这些程序类型大致分为三类:
- 跟踪:从内核和程序的运行状态中提取跟踪信息,来了解当前系统正在发生什么
- 网络:对网络数据包进行过滤和处理,以便了解和控制网络数据包的收发过程
- 其他类别:除跟踪和网络之外的其他类型,包括安全控制、BPF 扩展等等
下边列举了每一类 eBPF程序都有哪些具体的类型,以及不同类型的程序都是由哪些事件触发执行的。
跟踪eBPF程序
主要用于从系统中提取跟踪信息,进而为监控、排错、性能优化等提供数据支撑。 比如,前边的 Hello World 示例就是一个 BPF_PROG_TYPE_KPROBE 类型的跟踪程序,它的目的是跟踪内核函数是否被某个进程调用了。
常见的跟踪类 BPF 程序的主要功能以及使用限制如下:
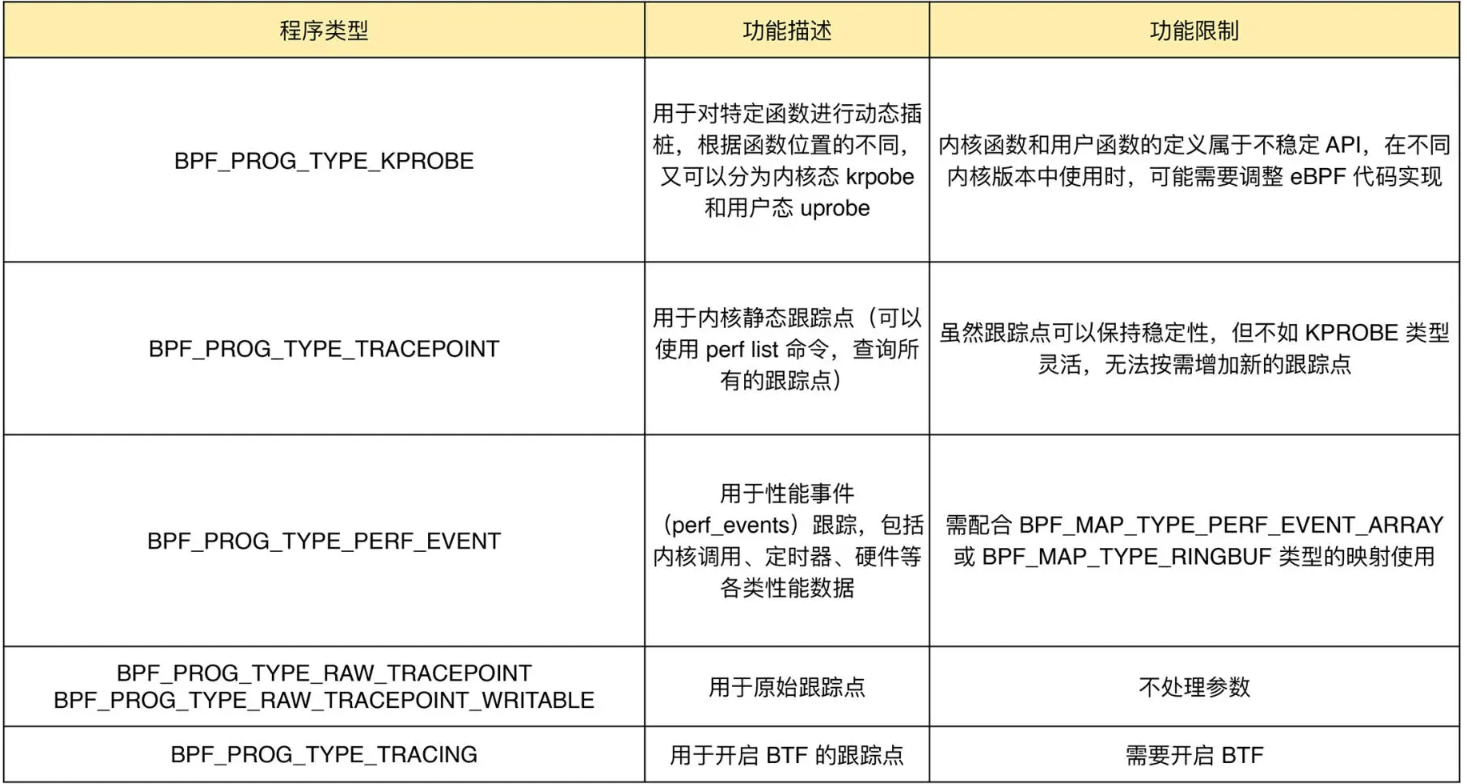
KPROBE、TRACEPOINT 以及 PERF_EVENT 都是最常用的 eBPF 程序类型,大量应用于监控跟踪、性能优化以及调试排错等场景中。BCC 工具集中,包含的绝大部分工具都属于这个类别。
网络类eBPF程序
网络类 eBPF 程序主要用于对网络数据包进行过滤和处理,进而实现网络的观测、过滤、流量控制以及性能优化等各种丰富的功能。 根据事件触发位置的不同,网络类 eBPF 程序又可以分为 :
- XDP(eXpress Data Path,高速数据路径)程序
- TC(Traffic Control,流量控制)程序
- 套接字程序
- cgroup 程序
XDP程序
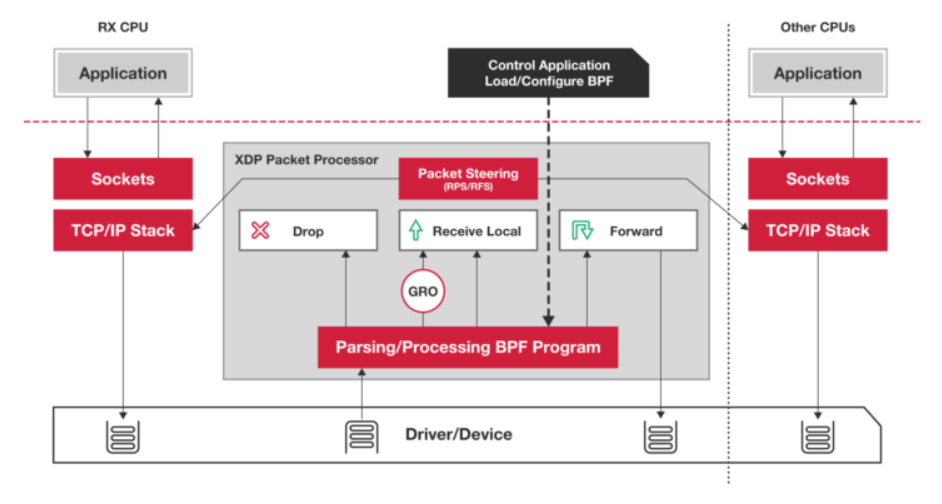
XDP 程序的类型定义为 BPF_PROG_TYPE_XDP,它在网络驱动程序刚刚收到数据包时触发执行。
应用:由于无需通过繁杂的内核网络协议栈,XDP 程序可用来实现高性能的网络处理方案,常用于 DDoS 防御、防火墙、4 层负载均衡等场景。
XDP 程序并不是绕过了内核协议栈,它只是在内核协议栈之前处理数据包,而处理过的数据包还可以正常通过内核协议栈继续处理。
根据网卡和网卡驱动是否原生支持 XDP 程序,XDP 运行模式可以分为下面这三种:
- 通用模式。它不需要网卡和网卡驱动的支持,XDP 程序像常规的网络协议栈一样运行在内核中,性能相对较差,一般用于测试;
- 原生模式。它需要网卡驱动程序的支持,XDP 程序在网卡驱动程序的早期路径运行;
- 卸载模式。它需要网卡固件支持 XDP 卸载,XDP 程序直接运行在网卡上,而不再需要消耗主机的 CPU 资源,具有最好的性能。
无论哪种模式,XDP 程序在处理过网络包之后,都需要根据 eBPF 程序执行结果,决定数据包的去处。这些执行结果对应以下 5 种 XDP 程序结果码:
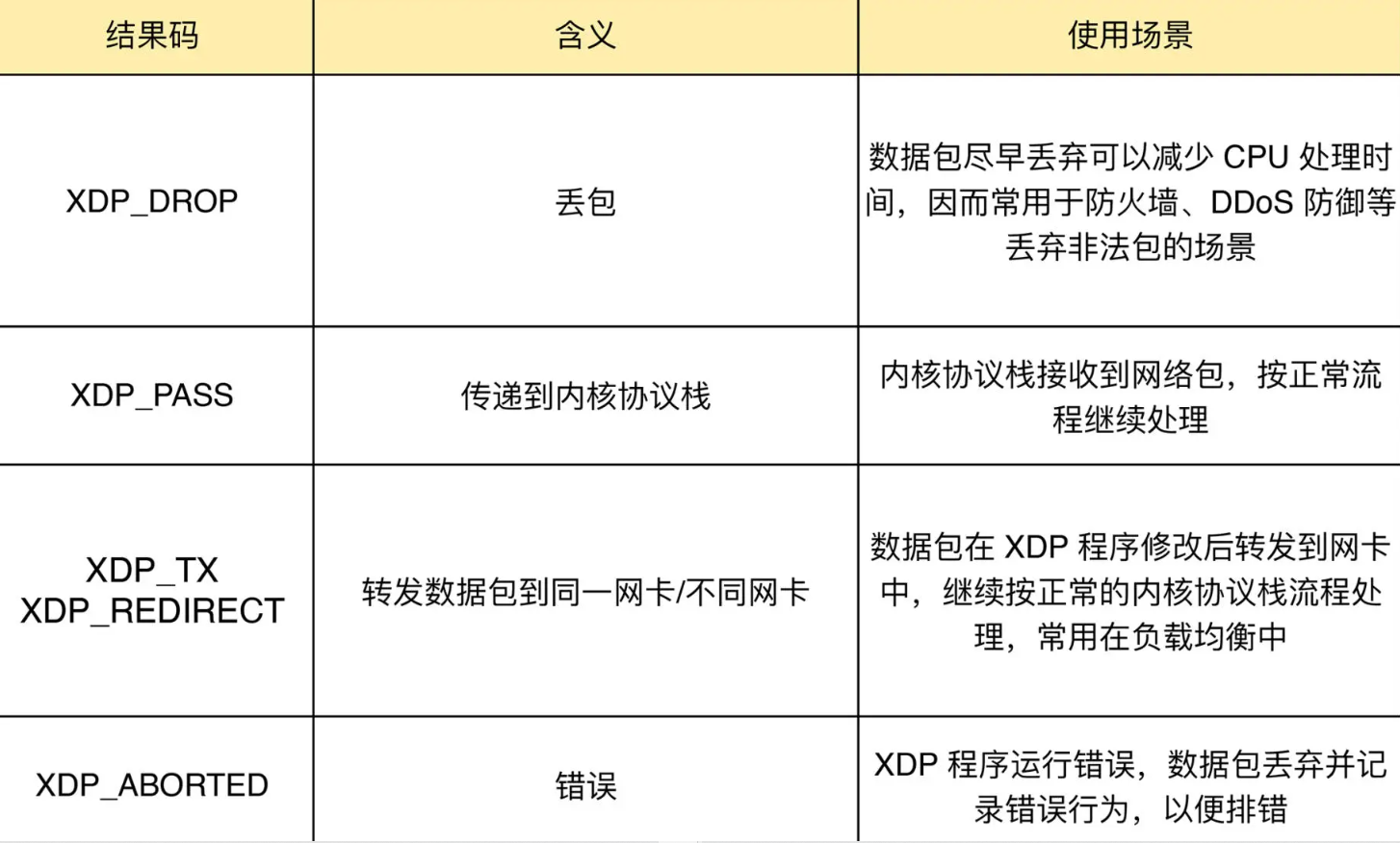
XDP程序 加载到具体网卡命令:
1
2
3
4
|
# eth1 为网卡名
# xdpgeneric 设置运行模式为通用模式
# xdp-example.o 为编译后的 XDP 字节码
sudo ip link set dev eth1 xdpgeneric object xdp-example.o
|
卸载XDP程序:
1
|
sudo ip link set veth1 xdpgeneric off
|
除了ip link命令外,BCC也提供方便的库函数,可以在同一个程序中管理 XDP程序的生命周期,示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
from bcc import BPF
# 编译XDP程序
b = BPF(src_file="xdp-example.c")
fn = b.load_func("xdp-example", BPF.XDP)
# 加载XDP程序到eth0网卡
device = "eth0"
b.attach_xdp(device, fn, 0)
# 其他处理逻辑
...
# 卸载XDP程序
b.remove_xdp(device)
|
TC 程序
TC 程序的类型定义为 BPF_PROG_TYPE_SCHED_CLS 和 BPF_PROG_TYPE_SCHED_ACT,分别作为 Linux 流量控制 的分类器和执行器。
Linux 流量控制通过网卡队列、排队规则、分类器、过滤器以及执行器等,实现了对网络流量的整形调度和带宽控制。
下边展示了 HTB(Hierarchical Token Bucket,层级令牌桶)流量控制的工作原理:
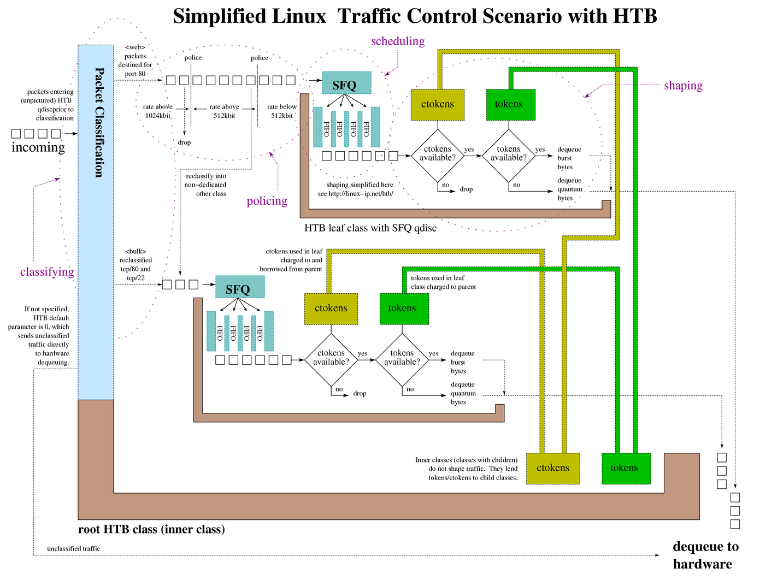
小贴士:Linux流量控制,可以参考 官方文档进行学习。
内核 v4.4 引入的 direct-action 模式,TC 程序可以直接在一个程序内完成分类和执行的动作,而无需再调用其他的 TC 排队规则和分类器,具体如下图所示:
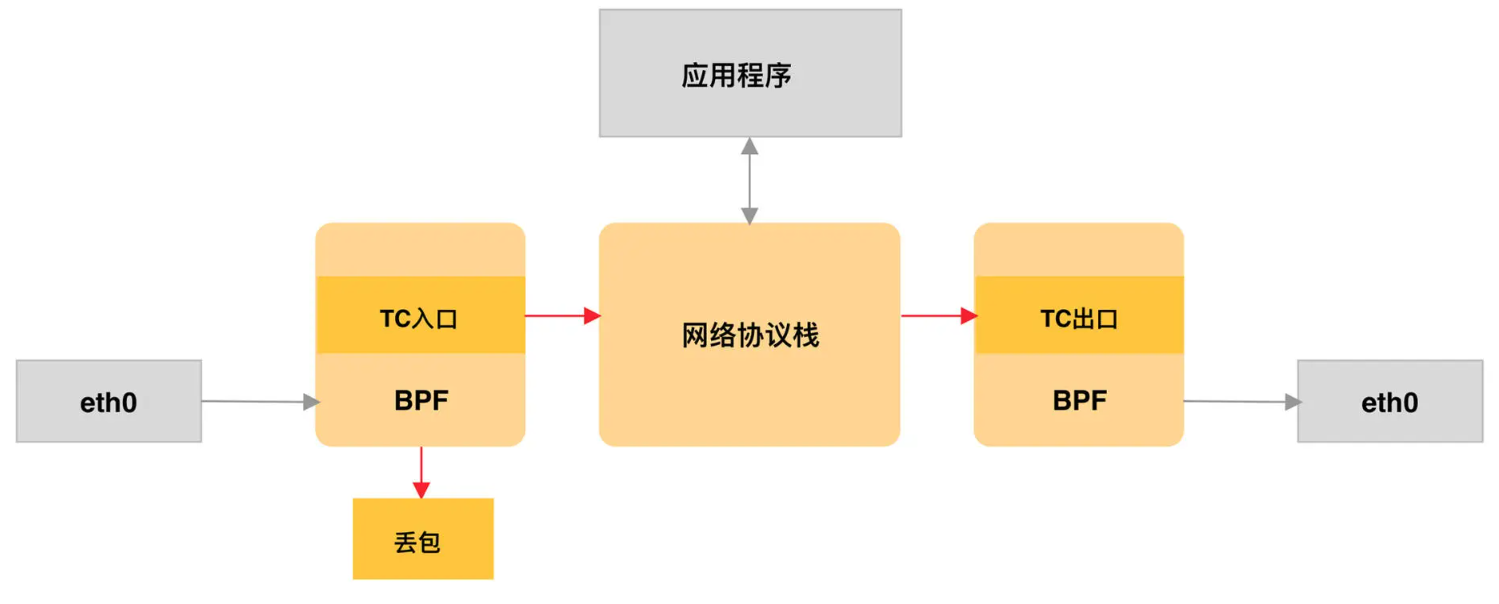
与 XDP 程序相比,TC 程序可以直接获取内核解析后的网络报文数据结构sk_buff(XDP 则是 xdp_buff),并且可在网卡的接收和发送两个方向上执行(XDP 则只能用于接收)。TC 程序的执行位置:
- 对于接收的网络包,TC 程序在网卡接收(GRO)之后、协议栈处理(包括 IP 层处理和 iptables 等)之前执行;
- 对于发送的网络包,TC 程序在协议栈处理(包括 IP 层处理和 iptables 等)之后、数据包发送到网卡队列(GSO)之前执行。
由于 TC 运行在内核协议栈中,不需要网卡驱动程序做任何改动,因而可以挂载到任意类型的网卡设备(包括容器等使用的虚拟网卡)上。
TC eBPF程序也可以通过 Linux 命令行工具来加载到网卡上。通过如下命令,分别 记载接收和发送方向的eBPF程序:
1
2
3
4
5
6
7
8
|
# 创建 clsact 类型的排队规则
sudo tc qdisc add dev eth0 clsact
# 加载接收方向的 eBPF 程序
sudo tc filter add dev eth0 ingress bpf da obj tc-example.o sec ingress
# 加载发送方向的 eBPF 程序
sudo tc filter add dev eth0 egress bpf da obj tc-example.o sec egress
|
套接字程序
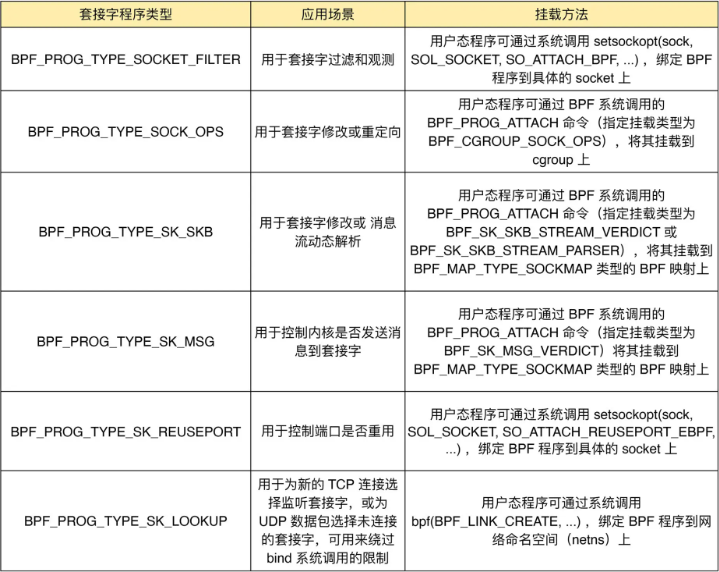
套接字程序用于过滤、观测或重定向套接字网络包,具体的种类也比较丰富。根据类型的不同,套接字 eBPF 程序可以挂载到套接字(socket)、控制组(cgroup )以及网络命名空间(netns)等各个位置。 可以根据具体的应用场景,选择一个或组合多个类型的 eBPF 程序,去控制套接字的网络包收发过程。
常见套接字程序类型,应用场景和挂载方法整理如下:
cgroup程序
用于对 cgroup 内所有进程的网络过滤、套接字选项以及转发等进行动态控制,它最典型的应用场景是对容器中运行的多个进程进行网络控制。
cgroup程序种类丰富,涉及到的BPF程序类型和应用场景整理如下:
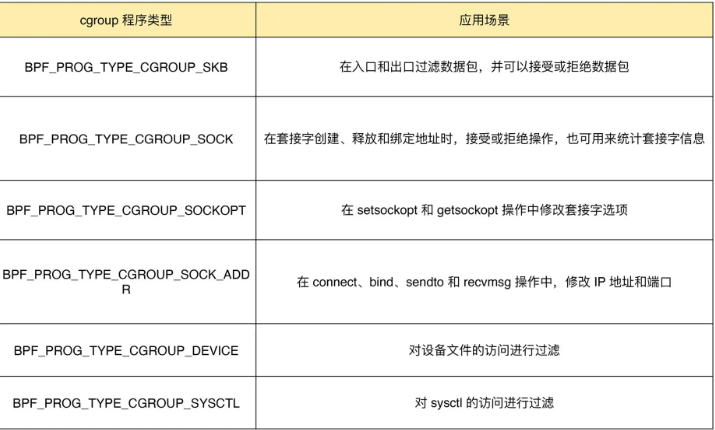
上述这些cgroup的BPF程序类型都可以通过 BPF 系统调用的 BPF_PROG_ATTACH 命令来进行挂载,并设置挂载类型为匹配的 BPF_CGROUP_xxx 类型。 比如,在挂载 BPF_PROG_TYPE_CGROUP_DEVICE 类型的 BPF 程序时,需要设置 bpf_attach_type 为 BPF_CGROUP_DEVICE,具体如下:
1
2
3
4
5
6
7
8
|
union bpf_attr attr = {};
attr.target_fd = target_fd; // cgroup文件描述符
attr.attach_bpf_fd = prog_fd; // BPF程序文件描述符
attr.attach_type = BPF_CGROUP_DEVICE; // 挂载类型为BPF_CGROUP_DEVICE
if (bpf(BPF_PROG_ATTACH, &attr, sizeof(attr)) < 0) {
return -errno;
}
|
小结
上述几类网络 eBPF 程序是在不同的事件触发时执行的,因此,在实际应用中我们通常可以把多个类型的 eBPF 程序结合起来,一起使用,来实现复杂的网络控制功能。
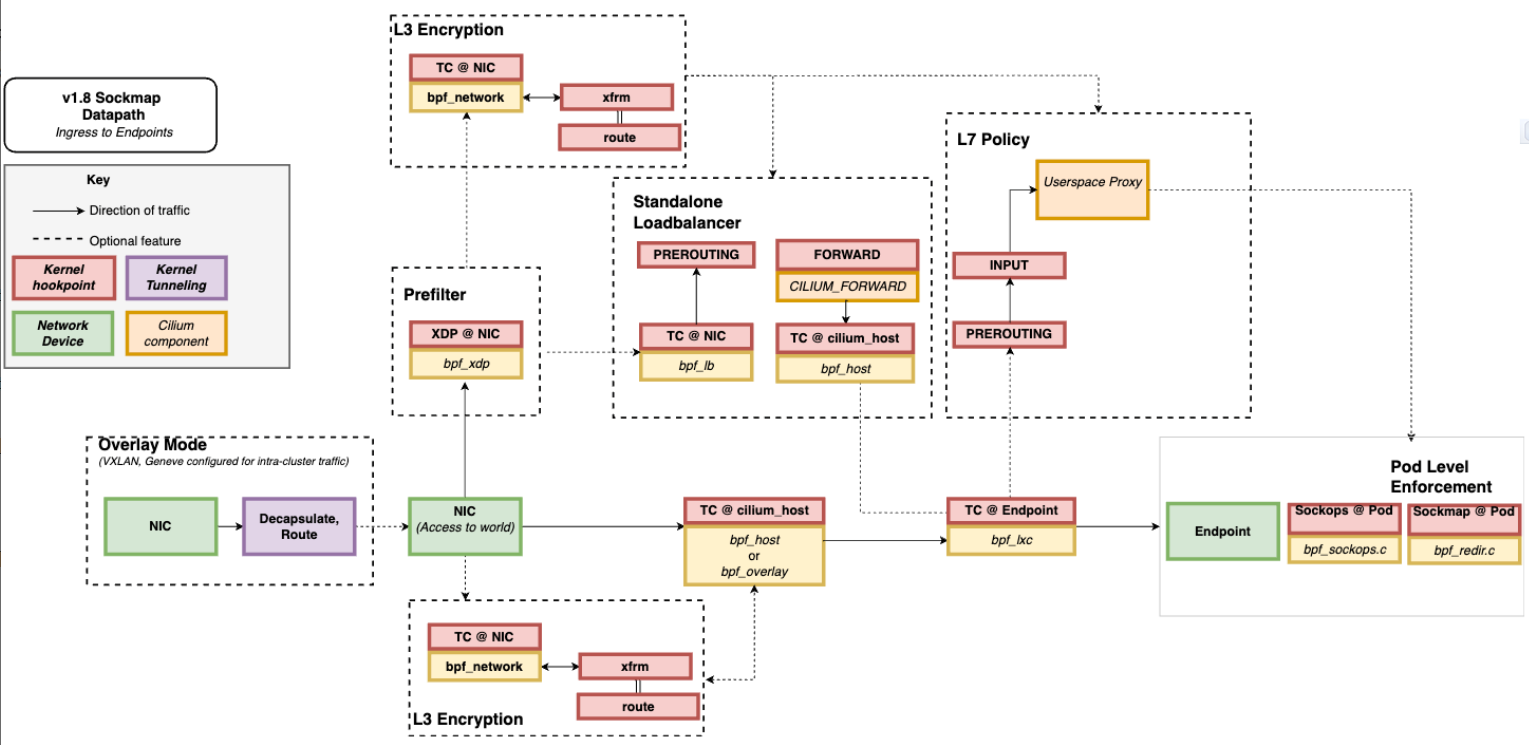
比如,最流行的 Kubernetes 网络方案 Cilium 就大量使用了 XDP、TC 和套接字 eBPF 程序, 如下图(图片来自 Cilium 官方文档,图中黄色部分即为 Cilium eBPF 程序)所示:
其他类别的 eBPF程序
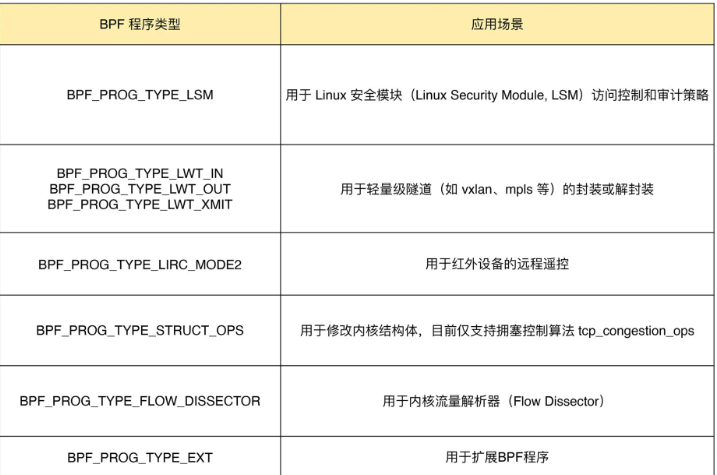
Linux 内核还支持很多其他的类型。这些类型的 eBPF 程序虽然不太常用,但在需要的时候也可以解决很多特定的问题。
无法划分到网络和跟踪的 eBPF 程序都归为其他类,并帮你整理了一个表格,如下:
小结
本小节 介绍 了eBPF 程序的主要类型,以及不同类型 eBPF 程序的应用场景。
根据具体功能和应用场景的不同,我们可以把 eBPF 程序分为跟踪、网络和其他三类:
- 跟踪类 eBPF 程序:主要用于从系统中提取跟踪信息,进而为监控、排错、性能优化等提供数据支撑;
- 网络类 eBPF 程序:主要用于对网络数据包进行过滤和处理,进而实现网络的观测、过滤、流量控制以及性能优化等;
- 其他类:包含了跟踪和网络之外的其他 eBPF 程序类型,如安全控制、BPF 扩展等。
每个 eBPF 程序都有特定的类型和触发事件,但这并不意味着它们都是完全独立的。通过 BPF 映射提供的状态共享机制,各种不同类型的 eBPF 程序完全可以相互配合,不仅可以绕过单个 eBPF 程序指令数量的限制,还可以实现更为复杂的控制逻辑。
附录
参考文献
版权信息
本文原载于kitebin.top,遵循CC BY-NC-SA 4.0协议,复制请保留原文出处。